이 포스트는 지난 5월 27일 “React 사용자를 위한 리액트 부트캠프“의 5일차 강의 때 사용한 발표자료와 스크립트를 글로 옮긴 것입니다. 스크립트를 거의 그대로 옮겼기 때문에 군데군데 구어체가 혼용되었으며 평소 블로그에서 쓰던 문체와도 다릅니다. 읽으실 때 양해 부탁드립니다.
실습을 위한 코드들이 다수 포함되어있기 때문에 모바일에서 읽기 불편할 수 있습니다. 저장해두신 후 PC에서 읽으시는 걸 권장드립니다.
컴포넌트를 잘 만드는 것이 왜 중요할까요?
컴포넌트는 리액트에서 가장 중요한 구성요소라고 말해도 과언이 아닙니다. 리액트로 만들어진 앱을 이루는 가장 최소한의 단위가 컴포넌트이기 때문이죠. 앱을 리액트로 만든다는 것은 곧 작고 단단한 컴포넌트들을 만들고 이 컴포넌트들을 유기적으로 연결한다는 것을 뜻합니다.
따라서, 잘 동작하는 리액트 앱을 만들기 위해서 우리는 크게 두 가지를 잘하면 됩니다.
- 작고 단단한 컴포넌트를 만드는 것
- 이렇게 만들어진 컴포넌트간의 관계를 정의하고 유기적으로 연결하는 것
이 강의에서는 “작고 단단한 컴포넌트를 만드는 것”에 좀 더 집중해보고자 합니다. 컴포넌트를 잘 만든다는 것은 사실 가장 당연하고 기본적인 일 같아보이지만 리액트 숙련자들도 종종 실수하는 부분이기도 합니다. 그래서 이 강의에서는 컴포넌트를 만드는데 가장 기본적인 원칙들을 정의하고 그걸 지키려고 노력하는데 주안점을 두고자 합니다. 사실 이것만 잘해도 본인을 고급 리액트 개발자라고 부를 수 있다고 생각해요.
컴포넌트란 무엇일까요?
그러려면 컴포넌트가 무엇인지 확실하게 파악하고 넘어가야겠죠. 컴포넌트라는 단위가 리액트에서 갖는 의미란 무엇일까요? 저는 근본적으로 컴포넌트란 데이터를 입력받아 DOM Node를 출력하는 함수라고 생각해요. 이 때 입력받는 데이터란 Props나 State 같은 것들이죠. 실제로도 React 공식 문서인 “Components and Props“를 보면 이런 문장이 있죠.
Conceptually, components are like JavaScript functions. They accept arbitrary inputs (called “props”) and return React elements describing what should appear on the screen.
이 강의에서 다룰 것들
이 강의에서 다루고 싶은 것은 이렇습니다. 시간이 허락한다면 다 하고 싶지만, 아마 불가능할 것 같네요.
- State를 분리하고 컴포넌트를 추상화하기
- React.memo & PureComponent
- Controlled / Uncontrolled 컴포넌트
- Functional Component with Hooks
- 글로벌 컴포넌트 (Portal)
- 컴포넌트 결합 패턴 (Component Composition)
이 강의에서 다루지 않을 것들
- Higher Order Component (HOCs)
- 스타일링 기법 (CSS Modules, CSS-in-JS 등)
- State Management (Redux, MobX 등)
HOC는 왜 다루지 않나요?
리액트에 Hooks API가 추가된 이래로 HOC는 더 이상 좋은 접근법이 아닙니다. 필요하다면 사용할 수 있겠지만 대부분은 Hooks로 대체할 수 있기 때문에 저는 사용을 추천하지 않습니다. 이번 강의에서는 HOC를 다루지 않습니다.
본격적인 강의 진행에 앞서 저의 모든 실습 코드는 Stackblitz를 사용할 예정이기 때문에 가능하시면 미리 가입해두시면 좋겠습니다. 또는 GitHub 계정으로 로그인 하셔도 됩니다.
Form
Form을 한 번 만들어볼게요. 우선 대부분의 웹사이트에서 가지고 있는 회원가입 페이지를 만든다고 가정해볼게요. 이 Form이 일반적으로 React에서 만드는 Form과 다른 점은 email, password 값을 State로 가지지 않고 클래스의 필드로 갖고 있다는 점인데요,
이 방법에는 장점과 단점이 있습니다. 장점은 render가 전혀 실행되지 않는다는 것이죠. 왜냐면 이벤트가 발생할 때 그걸 핸들링하기만 할 뿐, State는 전혀 갖고 있지 않거든요. State를 갖고 있지 않으니 State를 업데이트 할 수 없고, 이건 렌더가 다시 일어나지 않는다는 걸 의미하죠. 모든 동작은 Native DOM의 동작에 의존하게 되는 겁니다.
단점은 State가 없으니 State를 제어할 방법도 없다는 겁니다. React 단의 상태는 없지만, DOM 상의 상태는 있죠. 하지만 여기에 접근하고 있지 않기 때문에 React에서는 이걸 제어할 방법 자체가 없게 되는 겁니다. 만약 Form을 Reset하는 버튼이 필요하다면 어떻게 해야 할까요? 상태를 Reset하기 위해서는 React에서 반드시 State를 보유해야 합니다. State를 써봅시다.
이제 초기화 버튼까지 아주 잘 동작하네요! 지금 보신 이게 바로 Controlled 컴포넌트 입니다. 아까 보았던 State 가 없는 방식이 Uncontrolled 컴포넌트이고요.
Uncontrolled component & Controlled Component
Uncontrolled 컴포넌트는 방금도 말씀드렸지만 상태를 직접 React 에서 제어하지 않는다는 의미에서 Uncontrolled 컴포넌트로 불립니다. React 생태계에서는 사실 잘 쓰이지 않아요. 이렇게 상태를 프로그래머가 제어해야할 일이 종종 생기기 때문입니다. 하지만 아까도 말씀드렸듯이 렌더를 아예 타지않는다는 장점이 있기 때문에 상태를 제어할 일이 없다면 쓰는 것도 좋다고 생각해요.
Input 컴포넌트 만들기
사실 좀 더 정확하게 말씀드리면 흔히 Controlled 혹은 Uncontrolled라고 부를 때의 차이는 이게 끝이 아닙니다. 이걸 이해하기 위해서 <Input/> 컴포넌트를 만들어볼게요. 우리가 사용하고 있는 type, placeholder, value, onChange를 props로 넘겨받아야 겠네요.
그리고 보통 리액트에서 사용하는 방식은 아니지만 render가 호출되는 횟수를 측정해보기 위해 render에 다음과 같이 console.log를 집어넣을게요. 그리고 똑같이 이메일과 비밀번호를 입력해봅시다.
자 어떤가요? 지금은 이메일을 입력하고 있는데 불필요하게 비밀번호 Input의 render 함수가 호출되고 있습니다. 이걸 해결하기 위해서는 두가지 방법이 있습니다.
Uncontrolled Component
첫번째로는 이 Input 컴포넌트를 Uncontrolled 컴포넌트로 고치는 겁니다. 다만 JoinForm의 관점으로 보았을 때 Uncontrolled 인것이지 React 단에서 상태를 만들지 않겠다는 건 아닙니다. Input 컴포넌트의 내부에 상태를 만들겠다는 얘기죠.
자, 이렇게 JoinForm 내부에서 가지는 상태까지 제거하면 이제 완성입니다. 똑같이 이메일과 비밀번호를 입력해보면 이메일이 입력될 때 비밀번호 Input 컴포넌트의 render가 호출되지 않습니다! 성공인가요? 아닙니다. 초기화가 동작하지 않아요!
Uncontrolled Component에서 초기화를 동작시키게 하기 위해서 약간은 Tricky한 방법을 써야합니다. Form에 한가지 상태를 추가하고 그 상태를 Input 컴포넌트의 key 프로퍼티로 내려줍니다.
짠! 잘 동작하죠? 왜 이런걸까요?
key라는 프로퍼티는 React에서 특수하게 다루어지는 프로퍼티입니다. 사실 Array.map 메소드를 통해 배열을 컴포넌트 노드로 렌더시켜 보신적 있다면 아마 알고계신 프로퍼티일 것 같아요. key는 배열내에서 특정 아이템을 “identify”하기 위한, 특정짓기 위한 도구에요. 따라서 React의 관점에서 key가 다른 노드는 그냥 다른 노드로 분류되는 것이죠. 예를 들어 여기서 key만 바꿔준 email-1과 email-2 는 우리 입장에서 봤을 때는 같은 것 같지만, React의 관점에서는 아예 다른 노드인겁니다.
그래서 우리가 email-1을 email-2로 바꾸면 React에서는 email-1 인스턴스가 사라졌다고 인식해 email-1을 아예 지워버리고, 새롭게 email-2를 그리는 겁니다. 즉, 이렇게 key를 바꾸게 되면 단순히 상태가 초기화 되는 것이 아니라 컴포넌트 인스턴스 자체가 사라진 후, 다시 생깁니다. 이게 너무 빠르니 마치 상태가 초기화 된 것처럼 보이는 것이죠. (물론 이건 굉장히 단순화된 설명이에요.) 실제로도 각 컴포넌트의 renderCount마저 초기화된 걸 확인하실 수 있죠? 단순히 상태만 초기화된 거라면 이런일이 일어날 수 없을 겁니다.
참조: Recommendation: Fully uncontrolled component with a key
위 링크에서 이 기법에 대한 더 자세한 정보를 확인하실 수 있어요. 이렇게 컴포넌트를 제거하고 새로 만드는 작업은 당연하게도 State를 단순히 초기화하는 것보다 성능이 나쁠 거라고 예상하게 되지만, 실제로는 성능차이가 별로 중요하지 않은 수준이고 특정 상황에서는 State를 초기화는 것보다도 빠를 수 있다고 해요. 저는 사실 Uncontrolled Component를 선호하는 편입니다. State가 외부에 공개되지 않아서(캡슐화) 가지는 장점이 크다고 생각해요.
하지만 이 방법도 근본적으로 완벽하지는 않습니다. 우선 초기화에만 쓰는 상태가 하나 추가 되었다는 단점이 있고요. 또, JoinForm 입장에서 봤을 때 Input 컴포넌트를 원하는 값으로 만들어줄 방법이 없죠. 이제 두 번째 방법을 알아봅시다.
PureComponent
PureComponent는 사실 React에서 기본이라면 기본적인 내용입니다. 어찌보면 렌더링 Performance를 Optimize한다는 점에서 Advanced라고 볼 수도 있지만 누구든 쉽게 사용하니까요.
PureComponent와 일반 컴포넌트의 차이점은 간단합니다. Component는 항상 render를 다시 실행하지만 PureComponent는 Props나 State를 얕은 비교해서 변경점이 없으면 render를 다시 실행하지 않아요.
아까의 Input 컴포넌트로 돌아가서 Component를 PureComponent로 바꿔볼게요. 그리고 이메일을 입력해보면? 비밀번호는 다시 렌더링되지 않는걸 보실 수 있을겁니다. 비밀번호에 들어가는 Props의 값이 모두 이전과 같기 때문이죠. 이렇게 PureComponent를 잘 사용하면 렌더링 최적화와 Controlled Component라는 두 마리 토끼를 잡을 수 있습니다.
그렇다면 모든 컴포넌트를 PureComponent로 도배하면 좋지 않을까요? 그렇지는 않습니다.
Think about it. If component’s props are shallowly unequal more often than not, it re-renders anyway, but it also had to run the checks.
— Dan Abramov (@dan_abramov) January 15, 2017
만약 항상 re-render 되는 PureComponent가 있으면 의미가 없다는거죠. 아니, 어찌보면 불필요한 비교 로직이 들어가기 때문에 더 느리다는 의미입니다. 실제로도 이런 실수는 언제든 쉽게 발생할 수 있습니다.
PureComponent가 불리한 상황
이 예제를 보시면 마찬가지로 PureComponent를 사용함에도 불구하고, 관련없는 두개의 Input이 서로 렌더링되고 있는걸 확인하실 수 있습니다. 왜일까요?
바로 이전의 예제와 이 예제의 차이점은 이 예제에서는 인라인 함수를 썼다는 것입니다. 인라인 함수를 render 메소드 내에서 쓰면 매 render 실행시마다 함수 인스턴스가 새로 생성되겠죠? 따라서 이 코드를 실행되면 결과는 false로 출력됩니다.
1 | (() => null) === (() => null); // false |
이 말은 매 render 실행마다 Input에 Props로 내려오는 함수가 모두 다르다는 것이고, 함수의 실행과는 관계 없이 Shallow compare로 함수 자체가 다른지를 비교하기 때문에 항상 다르다는 결과를 반환하겠죠. 결론적으로 항상 re-render 되는 것입니다.
이런 상황은 인라인 함수 사용이 대표적이지만 이것 말고도 여러가지가 있습니다. 자주 부딪치는 문제중에서는 렌더 메소드 내에서 객체를 새로 만드는 케이스가 있죠. 이렇게요.
1 | class Parent extends React.Component { |
또 한 가지 정말 쉽게 실수할 수 있는 케이스는 ReactNode를 넘길 때, children등을 사용할 때 인데요, 이 부분은 조금 이따가 Component Composition을 할 때 다뤄보겠습니다.
Recap
- Uncontrolled Component는 사용자가 상태를 제어하지 않는 컴포넌트다.
- Uncontrolled Component는
keyProps를 이용해 초기화 할 수 있다.
- Uncontrolled Component는
- Controlled Component는 사용자가 상태를 제어할 수 있는 컴포넌트다.
- PureComponent를 이용해
render를 최적화 할 수 있다.- PureComponent는 Props와 State를 얕은 비교해서 이전과 같으면
render를 실행시키지 않는다 - PureComponent를 잘못 사용하면 일반적인 Component보다도 성능이 나빠질 수 있다.
- PureComponent는 Props와 State를 얕은 비교해서 이전과 같으면
Portal(Global) Component
일반적인 React 앱을 상상해보죠. View는 하나의 루트를 가지는 컴포넌트 트리입니다.
1 | <div id="root" />; |
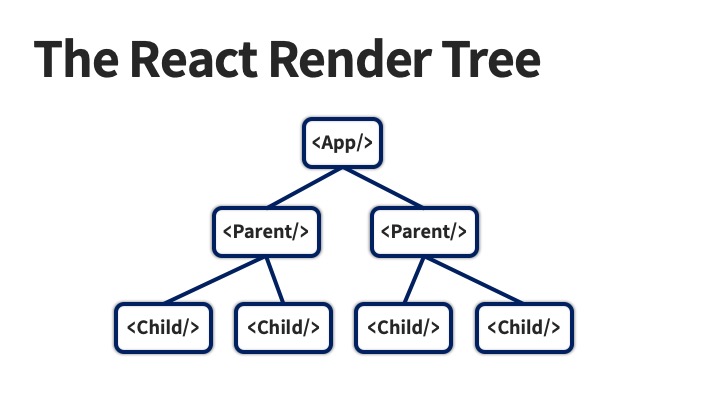
이 경우에 가장 꼭대기에 <App /> 이라는 이름의 컴포넌트가 렌더링 될 것이고 그 다음엔 이 컴포넌트가 가진 자식 컴포넌트가 렌더링 되고, 이게 가장 아래에 있는 컴포넌트까지 반복되겠죠. 결론적으로 컴포넌트의 계층 구조가 그대로 DOM의 계층 구조로 이어집니다. 그리고 “특별한 경우”가 아니라면 이 계층 구조를 역전할 방법이 전혀 없죠.
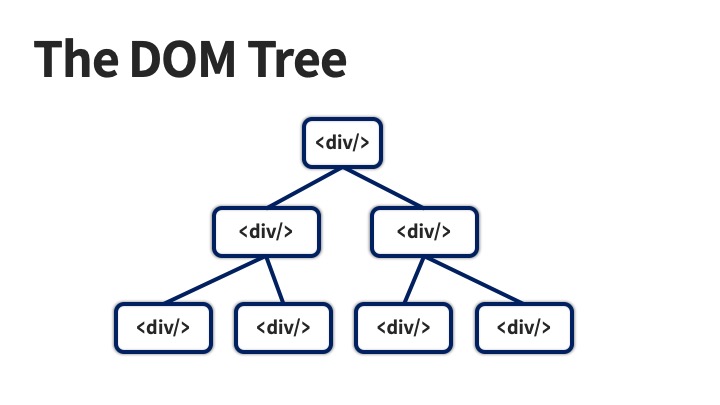
이 계층 구조는 대개의 경우 큰 문제가 없지만 React에서는 이 계층 구조가 불편한 상황이 가끔 생깁니다. 가령 컴포넌트 계층 구조로는 아래에 위치해야 하지만, 시각적으로는 상위 컴포넌트를 가려야하는 경우이죠. 그냥 position: fixed를 쓰면 된다고 생각하실 수도 있지만 사실 그렇지 않습니다.
Dialog를 표현하려고 했는데 Dialog가 부모한테 갇혀버렸습니다. 심지어 position: fixed를 쓴 상태임에도 불구하고 말이죠. CSS의 transform 속성이 동작하는 원리 때문인데요. 이 문제는 잘 알려진 문제중 하나고, 심지어 브라우저의 버그도 아닙니다. 아래 링크를 참조해보세요.
‘transform3d’ not working with position: fixed children
꼭 이게 아니더라도 쌓임 맥락, Stacking Context가 동작하는 원리 때문에 z-index를 아무리 높여도 원하는대로 동작하지 않는 현상, 한 번 쯤은 다들 경험해보셨을 거에요.
여튼 position: fixed나 z-index: 9999로 만사 해결할 수 없다는 건 이해하셨을 겁니다. 이 때 Portal이 필요합니다. 사용법은 간단해요. html 파일에 Portal의 컨테이너가 될 <div>를 하나 추가하고 해당 컨테이너를 대상으로 Portal을 렌더링 시키면 됩니다. 실제로 해볼까요?
차이점은 render 메소드에서 리턴을 할 때, 그냥 JSX를 쓰지않고, ReactDOM.createPortal을 호출해서 렌더될 컨테이너를 지정한 것 밖에 없죠. ReactDOM.render의 사용방식과 비슷하지 않나요? 이렇게 어렵지 않게 Portal을 사용할 수 있습니다. 이렇게 만들어진 컴포넌트는, 어느 컴포넌트 아래에 있건간에, Portal의 대상 컨테이너 아래에 렌더링 됩니다.
한 마디로 요약하자면 Portal 컴포넌트는 논리적으로 하위 컴포넌트여야 하는데, 시각적으로는 상위 컴포넌트를 덮어야 할 상황일 때 사용하면 됩니다.
Component Composition
React의 가장 좋은 점은 모듈의 단위가 컴포넌트라는 것이죠. 따라서 React에서는 컴포넌트 단위로 코드를 재사용할 수 있습니다.
일반적인 OOP에서는 상속이라는 기법을 통해 코드를 재사용하는데요. React에서는 상속이 굳이 필요할 만한 유즈케이스가 없다고 여기고, 상속을 지원하고 있지 않습니다. 대신 Composition, 합성을 지원하죠. 이 합성이라는 개념은 간단합니다. 컴포넌트에 다른 컴포넌트를 가져다 붙이는 거에요. 사실 그리고 children을 지원하는 컴포넌트는 합성도 지원한다고 볼 수도 있죠.
참고: Composition vs Inheritance - React
실습을 위해 위에서 만들었던 Dialog를 chlidren을 통해 합성을 지원하는 컴포넌트로 바꿔보도록 할게요.
간단하게 Dialog에 children 을 props로 받게끔 변경했어요. 자, 이제 부모 컴포넌트에서는 Dialog의 내부에 어떤 것이든 집어넣을 수 있습니다. 그리고 이게 바로 컴포넌트 합성이에요. 간단하죠?
이렇게 간단한 개념이지만, 어떻게 응용하느냐에 따라서 굉장히 강력한 기법입니다. 바로 위의 예제에서는 children이라는 props로 합성을 지원했는데, 실제로는 children 뿐만 아니라 다른 props로도 합성을 사용하실 수 있어요. 예제를 좀 더 개선해볼까요?
기존의 children을 지운 후, header, body, footer 를 받게 고쳤습니다. 그리고 부모 컴포넌트에서 각각의 props에 컴포넌트를 넣어볼게요. 어떤가요? 이런식으로 얼마든지 하나의 컴포넌트가 다른 컴포넌트를 받아서 렌더링 하게끔 동작시킬 수 있습니다.
저는 이런 컴포넌트를 Template(혹은 Template Component)이라고 부르는데요, 일반적으로 React 쪽에서 사용되는 용어는 아닙니다. 하지만 골격을 미리 잡아놓고 세부적인 부분을 채워넣는 것이 Template이라고 부르는 개념과 유사하다는 생각이 들지 않나요? 실제로 Atomic Design에도 Temnplate Component가 있는데 이걸 구현할 때도 보통 합성을 사용하게 됩니다.
Composition on PureComponent
아까 그냥 넘어갔던 PureComponent + children 얘기를 해볼게요. 이번에는 아까 만들었던 Dialog를 PureComponent로 바꿔보겠습니다. PureComponent는 Props와 State를 Shallow Compare해서 같으면 render를 실행시키지 않는다. 기억하시죠?
Dialog를 PureComponent로 바꾸고, Dialog의 render가 실행되지 않는지 확인해보기 위해서 <input/>을 하나 추가해 setState로 계속 상태를 바꿔볼게요. 어떻게 되나요? 뭔가를 <input/>에 타이핑할 때마다 Dialog가 다시 render를 실행시키는 걸 볼 수 있죠.
왜 이런걸까요? 문제는 아까와 같습니다. App의 render가 실행될 때마다 Dialog에 넘길 header, body, footer를 모두 새로 만들기 때문이에요.
1 | <h2>반가워요!</h2> === <h2>반가워요!</h2>; // false |
우리가 실제로 사용하는 JSX 문법은 실제로는 객체를, 보다 정확히 말하자면 ReactNode 객체를 생성합니다. 객체는 여러분들도 잘 아시겠지만 내부적으로는 데이터가 같아도 비교 연산자를 통해 비교해보면 다르다는 결과가 나오죠. 이 때문에 render 내에서 컴포지션을 지원하는 컴포넌트에 JSX로 생성한 ReactNode를 넘기면 매 번 렌더가 다시 됩니다. 이것은 children을 이용하더라도 마찬가지에요.
이 문제는 비교적 간단히 극복하실 수 있어요. render 내에서 ReactNode를 새로 생성하지 않으시면 됩니다.
이렇게 클래스의 프로퍼티로 넘길 ReactNode를 선언해놓고 쓰면 Dialog의 render가 다시 일어나지 않죠! 임시적으로 이렇게 사용가능하지만 사실 근본적으로 적절한 방법은 아니에요. Dialog가 Props로 ReactNode를 받고있는 한, 다시 실수할 여지가 생길 수 있거든요. 내가 아니더라도, 내 동료는 충분히 실수할 수 있죠. 동료 입장에서 Dialog가 PureComponent인지 아닌지 알게 뭔가요?!
따라서 ReactNode를 Props로 받는 컴포넌트.. 합성을 지원하는 컴포넌트라면 PureComponent를 쓰시는 것이 오히려 손해일 수 있습니다.
그렇지만.. Dialog의 render를 최적화할 방법은 없을까요? 이렇게 부모 컴포넌트의 상태가 업데이트 될 때마다 불필요한 render 호출은 합성된 컴포넌트에서 반드시 받아들여야 하는 일일까요?
물론 절대 그렇지 않습니다. 간단하게 Dialog를 래핑한 컴포넌트를 하나 더 만들기만 하면 문제는 해결됩니다.
WelcomeDialog라는 컴포넌트를 하나 더 만들었어요. PureComponent로요. Dialog는 Component로 고치고요. WelcomeDialog의 render 메소드내에서는 ReactNode를 그냥 생성하고 있죠. 왜냐하면 WelcomeDialog는 PureComponent이고, Props를 전혀 받지 않고 있기 때문에 render 가 다시 실행될 일이 없거든요. 따라서 Dialog도 다시 render 되지 않습니다.
이것을 React에서는 Specialization(특수화)이라고 부릅니다. 일반적인 목적의 컴포넌트를 좀 더 특수한 목적에 대응하는 컴포넌트로 만드는 것이죠.
Recap
- Portal 컴포넌트는 논리적으로 하위 컴포넌트지만 시각적으로는 상위 컴포넌트여야 할 때 사용한다.
- React에서는 합성, Composition을 통해 컴포넌트를 재사용할 수 있다.
- Composition을 지원하는 컴포넌트의 경우 PureComponent를 사용하면 성능이 나쁠 수 있다.
- Composition을 지원하는 컴포넌트를 최적화 하고 싶으면 특수화를 적용한다.
Functional Component
지금까지의 예제는 모조리 클래스 컴포넌트로만 작성했는데요. 여러분들도 잘 아시겠지만 React에서는 클래스가 아닌 함수를 써서 컴포넌트를 작성할 수 있습니다. 개인적으로는 컴포넌트라는 것 자체가 Props를 받아 Node를 렌더하는 함수에 가까운 개념이라는 점에서 함수형 컴포넌트를 더 선호하는 편입니다. 함수형 컴포넌트가 기본적으로 문법이 간결한 편이기도 하고요.
그리고 지난번에 React 16.8 버전이 릴리즈 되면서 Hooks라는 기능이 React에 추가되었는데요. Hooks가 추가되면서 앞으로는 class 컴포넌트 없이 함수형 컴포넌트로만 앱을 구성할 수 있게 되었습니다.
이번 시간에는 아까 짜보았던 코드들을 모두 Hooks를 사용해 함수형 컴포넌트로 전환하고 어떤 hook들이 있는지 알아보도록 할게요.
먼저 아까 짰던 Form에서 Input 컴포넌트를 함수형 컴포넌트로 바꿔봅시다. Input 컴포넌트에서는 그냥 Props를 내려주기만 했기 때문에 별 어려움은 없을거에요.
React.memo
다만 Input 컴포넌트는 PureComponent였죠. 때문에 PureComponent의 함수형 버전을 사용해야 합니다. 바로 React.memo에요. 별 다를 것 없이 만든 함수형 컴포넌트를 React.memo로 감싸기만 하면 됩니다.
그런데 이름이 왜 React.memo일까요? 함수형 프로그래밍의 memoization을 잘 알고 계시다면 답하기는 쉬울텐데요. 동작하는 방식이 함수형 프로그래밍의 memoization이랑 비슷하기 때문이에요. (근본적으로 같지는 않아요.) 함수형 프로그래밍에서의 memoization은 순수함수의 입력(인자)이 같으면 리턴하는 값도 항상 같다는 점을 이용해 한번 계산한 반환 값을 저장해두고 다음 입력이 들어올 때 저장된 값을 반환합니다. React의 React.memo는 “순수” 컴포넌트(PureComponent)에 들어갈 입력, 즉, Props, State가 같은 경우 같은 렌더링 결과가 나온다는 점을 렌더링에 이용하는 거죠. 다만 React.memo의 경우엔 어디다 결과를 저장해두고 반환한다기 보다는 Props와 State가 같으면 굳이 렌더링을 하지 않는 형태로 구현하는 겁니다.
useState
이번에는 JoinForm을 함수형 컴포넌트로 바꿔볼게요. 하지만 이번에는 난관이 하나 있습니다. 바로 JoinForm에는 State가 있다는 거죠.
이제 Hooks가 등장할 차례가 왔습니다. React 16.8 부터는 함수형 컴포넌트에서도 상태를 사용할 수 있도록 useState라는 hook을 제공합니다. 우선은 각종 이벤트 핸들러를 모두 지우고 딱 View만 남겨볼까요? 그리고 useState를 통해 상태를 구현해볼게요.
사용법은 간단합니다. useState의 인자로 초기화할 값을 넘기신 후에, 반환되는 배열의 첫번째 index 그리고 두번째 index의 아이템을 사용하면 됩니다. 이렇게요.
1 | const [email, setEmail] = useState(""); |
그리고 setEmail을 이용해서 onChange 에 넘겨줄 이벤트 핸들러를 만들면 되는거죠. password에도 똑같은 방식을 쓰면 됩니다.
useCallback
아까 제가 inline함수는 PureComponent에 쓰면 항상 렌더링을 유도하기 때문에 쓰면 안된다고 했던거 기억하시죠? 이렇게 함수형 컴포넌트는 함수의 본문자체가 render 함수이기 때문에 이벤트 핸들러를 어디서 만들건간에 계속해서 새로운 함수를 만들게 됩니다. React에서는 이 문제를 해결하기 위해서 또 다른 hook, useCallback을 제공합니다.
사용법은 간단해요. 쓰고싶은 함수를 useCallback으로 감싸고 두번째 인자에 빈 배열을 넘기시면 됩니다. 이렇게요.
1 | const handleChangeEmail = useCallback(({ target: { value } }) => { |
이렇게하면 렌더 시마다 새로운 함수를 생성하지 않고 항상 같은 함수 인스턴스를 반환하게 됩니다. 결론적으로 render 가 실행될때마다 handleChangeEmail에 할당되는 “값”이 항상 같은 거죠. 때문에 이제 Input은 다시 렌더링 되지 않습니다.
이제 나머지 이벤트 핸들러들을 하나씩 만들어볼게요. handleSubmit 함수를 작성해서 이메일과 비밀번호를 로그로 찍도록 만들게요.
1 | const handleSubmit = useCallback(() => { |
근데 뭔가 이상합니다. 이메일과 비밀번호를 아무리 타이핑해도 로그에 제대로 남질 않아요. 왜일까요? 이제 useCallback의 두 번째 인자로 넘기는 빈 배열에 대해 배워야 할 시간입니다. useCallback 에 넘기는 첫번째 인자는 클로저입니다. 이 함수가 생성되던 당시의 상태를 기억한다고 보면 되겠죠. 따라서 이 상태라면 항상 가장 초기 버전의 email, password를 출력하는 함수가 되는 겁니다. 결론적으로 이 상태의 callback 함수는 항상 string의 email, password만 갖고있겠죠.
이 문제를 해결하기 위해서 두 번째 인자가 존재하는 겁니다. 두번째 인자의 다른 이름은 “Dependency List” 인데요, 여기에 함수 내에서 참조하고 있는, 즉 의존하고 있는 값을 넣습니다. 가령 handleSubmit에서는 email과 password를 외부에 의존하고 있죠. 이제 이 두 값을 배열에 넘겨볼게요. 이제 잘 동작하죠?
이게 필요한 이유는 아까도 말했듯이 useCallback의 인자로 넘어가는 함수는 클로저의 원리를 이용해 구현된 것인데, 문제는 클로저에서는 생성된 당시에 값을 기억하지만 그 값이 업데이트되면 의미가 없어지는 겁니다. 따라서 그 값이 업데이트될 때마다 함수를 새로 만들어야 합니다. 그 기준이 두 번째 인자로 넘기는 배열, Dependency List 입니다.
useCallback 에서는 Dependency List를 이전에 넘겨 받은 값과 shallow compare로 비교해서 다르다고 판단하면 새로운 함수를 만들고, 아니라면 이전에 만들어진 함수를 그대로 유지합니다. 결과적으로, 이제는 email혹은 password가 바뀔 때마다 새로운 함수가 생성되고 있는 셈이죠.
마지막으로 “초기화”를 구현해볼게요. 간단하게 setEmail그리고 setPassword가 호출되게 구현하면 완료입니다!
useMemo
Input 컴포넌트를 조금 업데이트해서 컴포지션이 가능하도록 변경해볼게요. useRef를 이용해서 렌더링 횟수를 측정할텐데 useRef에 대해서는 조금 이따 얘기해볼게요. 일단은 accessory 라는 Props를 추가한 뒤 여기로 버튼을 넘기겠습니다. 이 버튼은 동적으로 렌더링이 될거에요. email이 빈 값이 아닐 때만 표시되도록 만들어 보겠습니다. 이렇게요.
1 | <Input |
비밀번호도 마찬가지 작업을 해주고, 이메일 영역에 몇글자 쳐서 버튼을 나타나게 한다음에, 비밀번호를 타이핑 해볼게요. 어떤가요? 불필요하게 이메일 Input 컴포넌트가 렌더링되기 시작했죠?
이유는 여러분들도 쉽게 짐작하실 수 있겠지만 컴포지션을 사용했기 때문입니다. 아까 컴포지션을 다루면서 Props로 ReactNode를 넘기는 경우의 단점에 대해서 언급한 것 기억하시죠? 렌더구문안에서 항상 새로운 ReactNode가 생성되기 때문에 매번 렌더가 다시 실행되는 것이죠. 이 문제를 막기 위해 useCallback 을 사용했던 방식과 동일하게 useMemo를 사용할 수 있습니다.
1 | const emailAccessory = useMemo(() => { |
React 공식문서에서는 heavy한 작업에 useMemo를 쓰라고 권장하고 있지만 실제로 프론트엔드에서 헤비한 작업을 하게 될 일보다는 이렇게 PureComponent의 불필요한 re-render를 막기 위해서 사용하는 케이스가 더욱 흔할 것 같아요.
useRef
이제 아까 그냥 넘어갔던 useRef 에 대해서 얘기해볼게요. React의 ref 개념에 대해서는 다들 알고 계시나요? 보통은 React 상에서 DOM 객체에 접근할 때 사용하던 기능이었죠. useRef도 마찬가지로 그렇게 사용합니다. 이메일 필드의 DOM 객체를 얻어오기 위해 useRef를 사용해볼게요.
Input 컴포넌트 안에서 useRef 를 사용해서 DOM 객체를 담을 컨테이너를 생성합니다. 그리고 input에 넘겨주면 되죠. console.log를 찍어서 확인해보면 첫번째 렌더링때는 제대로 안나오지만 두 번째 렌더링 때부터는 잘 나오는 걸 보실 수가 있죠.
하지만 useRef의 기능은 이것으로 끝이 아닙니다. 클래스로 컴포넌트를 짤 때도 State가 아닌 필드를 선언하는 경우가 종종 있었죠? 그런 경우는 대개 렌더링에 영향을 미치는 값이 아니지만, 각 노드 인스턴스별로 달라야 하는 값입니다. 그런 것들 중 가장 대표적으로 DOM 객체가 있는 것이고요. 이런 식으로 각 노드별로 렌더링된 횟수를 재고 싶을 때도 필요하죠. 각 노드별로 가져야하는 값인데, 이 값이 변경 될 때마다 렌더가 실행될 필요가 없으면 useRef를 사용하기에 딱 적절한 상황입니다. State를 사용하게 되면 업데이트 때마다 render가 호출될테니까요.
useEffect
useEffect는 렌더가 완료된 후에 호출되는 콜백이라고 생각하면 편합니다. componentDidMount와 componentDidUpdate가 실행되는 시점을 합하면 useEffect가 실행되는 시점이라고 볼 수 있죠. 우리가 componentDidMount에서 종종 Data Fetching을 했던 것처럼 useEffect는 Data Fetching 같은 Side Effect를 발생시킬 때 쓰는 hook 이에요.
useRef에 useEffect를 결합해 컴포넌트가 마운트 되었을 때 자동 포커스 되는 기능을 구현할 수 있습니다. 사실 “포커스”라는 것 자체가 일종의 Side Effect죠. 아까 만들었던 Input에 autoFocus라는 Props를 추가하고 이 속성이 true 일때만 마운트되었을때 포커스가 가게끔 구현해볼게요.
먼저 Input에 autoFocus Props를 추가했고, useEffect에 마운트되고 난 뒤 실행될 콜백을 선언합니다. autoFocus가 true일 때만 inputElement.current.focus() 를 실행할게요. 여기에도 마찬가지로 dependency list가 두번째 인자로 넘겨야 하는데요. 실제로 의존하고 있는 Props인 autoFocus를 배열에 넘기도록 할게요. 만약 여기에 빈 배열을 넘기게되면 componentDidMount와 거의 똑같이 동작합니다. 그리고 특정 값을 배열에 넘기게되면 그 값이 바뀔 때마다 넘긴 콜백이 실행되는 것이구요.
componentWillUnmount는요?
useEffect에 넘겨준 callback에 리턴할 때 함수를 넣어주면 Unmount되면서 실행됩니다. componentWillUnmount 처럼요. 실험해볼까요? 아까 만든 Input 렌더링에 조건을 걸게요. 가령 email 값이 ‘abcd’일 때만 렌더링 하도록 말이죠. 그리고 Input 컴포넌트에 있는 useEffect에 다른 걸 다 빼고 함수하나를 만들어 return 하도록 만들어봅시다. 로그를 출력해서 언제 실행되는지 볼 수 있게 만들고요. 어떻게 되나요?
React에서는 이걸 “Cleanup”이라고 부릅니다. 언뜻보면 기존 componentDidMount / componentWillUnmount보다 비직관적으로 보이지만, 이런 접근 방식의 장점은 같은 관심사를 가진 로직을 한데 묶어놓을 수 있다는 점입니다. 이 부분은 Custom Hook 쪽에서 좀 더 자세히 설명할게요.
Custom Hook 만들기
다시 JoinForm으로 돌아올게요. JoinForm에는 약간의 중복이 있어요. 이메일과 비밀번호에 사용할 State를 만들고 Input에서 이벤트를 받아 State를 업데이트하는 부분은 이메일과 비밀번호에 공통적으로 적용되는 부분이죠.
Custom hook을 만들면 이렇게 중복되는 로직을 묶어서 추상화하고, 이걸 재사용할 수 있어요. 이번엔 useInputState 라는 이름의 hook을 만들어서 이걸 어떻게 구현하는지 알아볼게요.
먼저 useInputState라는 파일을 만들어놓고, 중복되는 로직을 차례차례 옮겨봅시다. 공통적으로 사용되는 useState를 옮겨보죠. 초기 상태가 필요하기 때문에 초기 상태 값은 parameter를 통해서 받습니다. 그리고 useCallback을 통해 이벤트 처리하던 부분을 옮깁니다. 마지막으로 이렇게 해서 만든 것들을 배열로 리턴합니다.
받는 쪽에서는 useState를 사용할 때 처럼 배열에 있는 것들을 destructuring해서 사용하면 됩니다. 그리고 아까처럼 컴포넌트 Props로 값을 전달해주면? 잘 동작하죠!
아까 HOC를 다루지 않겠다고 했던 이유가 여기에 있습니다. HOC와 hooks가 해결하는 문제는 비슷합니다. 그건 바로 Control Logic의 재사용인데요. HOC는 로직과 컴포넌트를 강력하게 연결한다면 hooks는 로직을 느슨하게 연결함으로서 좀 더 유연하게 코드를 작성할 수 있습니다.
이번에는 조금 다른 종류의 hook을 만들어볼게요. 어떤 컴포넌트에서 window가 resize 될 때마다 변경된 window width의 값을 구독해 렌더링에 반영시킬 수 있는 hook입니다. 먼저 useState로 상태를 담을 변수를 만들어 줍니다. 그리고 useEffect를 통해 window의 resize 이벤트를 구독하도록 할게요. removeEventListener를 호출하지 않는다면 addEventListener에 전달한 이벤트 핸들러가 계속해서 메모리에 남아있을테니 퍼포먼스에 악영향을 미칠 겁니다. 따라서 addEventListener에 전달하는 이벤트 핸들러는 useEffect에 전달하는 콜백 스코프에서 만들도록하고, 컴포넌트가 unmount 될 때, removeEventListener를 통해 이벤트 핸들러를 지워주세요. 이렇게하면 이벤트 핸들러가 컴포넌트의 생명 주기를 따라갈 수 있을 겁니다. (예제 개선에 도움을 주신 @KrComet님 감사합니다!)
그리고 여기서 useEffect의 진가가 드러납니다. 기존의 방법대로라면 addEventListener는 componentDidMount에, removeEventListener는 componentWillUnmount에 위치했을 것이고 이벤트 핸들러는 클래스의 프로퍼티로 별도의 함수로서 존재했을 것입니다. “Resize 이벤트 핸들링”이라는 같은 관심사를 공유하는 코드들이 멀찍이 흩어져있었겠죠. useEffect를 사용함으로서 같은 관심사를 공유하는 코드를 한데 모아놓을 수 있습니다. 읽기 훨씬 수월하겠죠?
Rules of Hooks
이렇게 편리하고 좋은 Hook이지만 사용하기 위해서는 다음과 같이 반드시 지켜야 할 규칙이 있습니다.
- Hook은 항상 컴포넌트 렌더로직의 Top Level 스코프에서 호출되어야만 합니다.
- 즉, Hook을 if, for 문 혹은 다른 함수의 callback에서 사용하면 안됩니다.
- 이것은 모든 render에 hook 호출 순서가 항상 같아야 하기 때문입니다.
- Hook을 React 함수(Funcitonal Component, Custom hooks)가 아닌 다른 곳에서 호출하면 안됩니다.
저는 사실 이런 Rule이 별로 어렵지도 않고 헷갈리지도 않아 지키기 어렵다는 생각이 지금까지 들지는 않았는데요. 어쨌든 사람이 실수할 수 있는 부분인 것도 분명한지라 React에서는 이런 Rule을 쉽게 지킬 수 있도록 eslint 플러그인을 제공합니다. 이 플러그인에는 추가적으로 “exhaustive-deps”라는 룰도 포함되어 있는데요. 이 룰은 Dependency List에 전달해야하는 의존성을 빼먹으면 알려주는 Rule입니다. 이쪽은 빼먹기 쉬운 부분이라서 상당히 유용합니다.
Recap
- Hook이 들어오면서 대부분의 컴포넌트는 클래스를 쓰지않고 구현이 가능하다.
React.memo는 함수형 컴포넌트의 PureComponent다.useState를 통해 함수형 컴포넌트의 상태를 구현할 수 있다.useCallback,useMemo를 통해 함수형 컴포넌트 렌더링 최적화를 할 수 있다.useRef는 렌더링에 영향을 미치지 않는 값을 보관할 용도로 사용한다.useEffect는 클래스의 Lifecycle 훅과 흡사하다.- 이미 나와있는 hook들을 이용해서 hook을 직접 만들 수도 있으며, 로직을 추상화, 재사용하는데 유리하다.
Retrospect
제 인생 첫 강의였습니다. 제가 선택한 주제가 결코 만만하지 않아서 준비하는데 애를 많이 먹었던 것 같아요. 제가 생각하는 이상적인 강의의 청사진 같은게 있었는데, 전혀 구현하지 못했습니다. (그래서 강의의 제목이 바뀐 것이기도 하고요.) 단순히 이상적인 그림을 상상하는 것과 실제로 그걸 구현해가면서 오는 괴리가 생각 이상으로 크더라구요. 그래서 처음에 제가 구성한 아웃라인과는 다른 강의가 되어버렸습니다.
다루고 싶은 내용은 더 많았어요. Atomic Design이라던가, Form 만드는 방법과 Formik 같은 라이브러리, Animation Component 그리고 Presentational / Container Component 같은 기법들 말이죠. 강의를 준비하는 시간 자체를 많이 투자하지 못해서 해당 내용을 모두 준비하지 못했던 것 같습니다. 아쉽기도 하고 죄송하기도 하네요.
강의를 할 때는 오디오가 빌 때마다 이상하게 마음속에 부담이 생겨서 오디오가 비지 않게끔 계속해서 말을 이어가려고 했던 것 같은데, 결과적으로 횡설수설에 버벅거리면서 아무 말이나 했던 것 같아서 어떤 분들은 듣기 좀 어려웠을 것 같아요. 결과적으로 강의가 끝나고 집에 오니까 목이 많이 아프더라고요.. 😅 그리고 제 생각에는 너무 일방적으로 말을 쏟아내다보니 듣는 입장에서 많이 지루했을 수도 있을 것 같아요. 진행도 일방적으로 했던 것 같고요.
그래도 마치고나니 뿌듯한 마음이 듭니다. 모쪼록 모든 분들께 제 강의가 조금이라도 도움이 되었으면 좋겠네요. 🙏 4시간이라는 짧지 않은 시간 동안 부족한 제 강의를 들어주신 모든 분들께 감사드립니다. 🙇